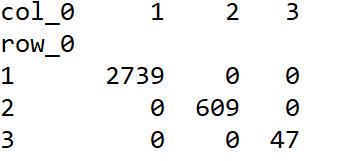数据挖掘之聚类分析总结(建议收藏)
|
hcluster.dendrogram(linkage, truncate_mode='lastp', p=12, leaf_font_size=12.)
#对聚类得到的类进行标注 层次聚类的结果,要聚类的个数,划分方法 (maxclust,最大划分法)ptarget = hcluster.fcluster(linkage, 3, criterion='maxclust')#查看各类别中样本含量 pd.crosstab(ptarget,ptarget)
绘制图形 #使用主成分分析进行数据降维 pca_2 = PCA(n_components=2) data_pca_2 = pd.DataFrame(pca_2.fit_transform(data[cloumns_fix1]))
plt.scatter(data_pca_2[0], data_pca_2[1], c=ptarget) #绘制图形 3、 DBSCAN密度法概念: 中文全称:基于密度的带噪声的空间聚类应用算法,它是将簇定义为密度相联的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据集中发现任意形状的聚类。 密度:空间中任意一点的密度是以该点为圆心,以Eps为半径的园区域内包含的点数目。 邻域:空间中任意一点的邻域是以该店为圆心,以Eps为半径的园区域内包含的点集合。 核心点:空间中某一点的密度,如果大于某一给定阈值MinPts,则称该点为核心点。(小于MinPts则称边界点) 噪声点:既不是核心点,也不是边界点的任意点 DBSCAN算法的步骤: 通过检查数据集中每点的Eps邻域来搜索簇,如果点p的Eps邻域内包含的点多于MinPts个,则创建一个以p为核心的簇 通过迭代聚集这些核心点p距离Eps内的点,然后合并成为新的簇(可能) 当没有新点添加到新的簇时,聚类完成 DBSCAN算法优点: 聚类速度快且能够有效处理噪声点发现任意形状的空间聚类 不需要输入要划分的聚类个数 聚类簇的形状没有偏倚 可以在需要是过滤噪声 DBSCAN算法缺点: 数据量大时,需要较大的内存和计算时间 当空间聚类的密度不均匀、聚类间距差较大时,得到的聚类质量较差(MinPts与Eps选取困难) 算法效果依赖距离公式选择,实际应用中常使用欧式距离,对于高纬度数据,存在“维度灾难” https://baike.baidu.com/item/维数灾难/6788619?fr=aladdin python中的实现 1)数学原理实现 导入一份如下分布的数据点的集合。
#计算得到各点间距离的矩阵 from sklearn.metrics.pairwise import euclidean_distances dist = euclidean_distances(data) 将所有点进行分类,得到核心点、边界点和噪声点。 #设置Eps和MinPts eps = 0.2 MinPts = 5
ptses = [] for row in dist: #密度 density = np.sum(row<eps) pts = 0 if density>MinPts: #核心点,密度大于5 pts = 1 elif density>1 : #边界点,密度大于1小于5 pts = 2 else: #噪声点,密度为1 pts = 0 ptses.append(pts) #得到每个点的分类 以防万一,将噪声点进行过滤,并计算新的距离矩阵。 #把噪声点过滤掉,因为噪声点无法聚类,它们独自一类 corePoints = data[pandas.Series(ptses)!=0] coreDist = euclidean_distances(corePoints) 以每个点为核心,得到该点的邻域。 cluster = dict() i = 0 for row in coreDist: cluster[i] = numpy.where(row<eps)[0] i = i + 1 然后,将有交集的邻域,都合并为新的领域。 for i in range(len(cluster)): for j in range(len(cluster)): (编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |