阿里是如何抗住双11的?看完这篇你就明白了!
|
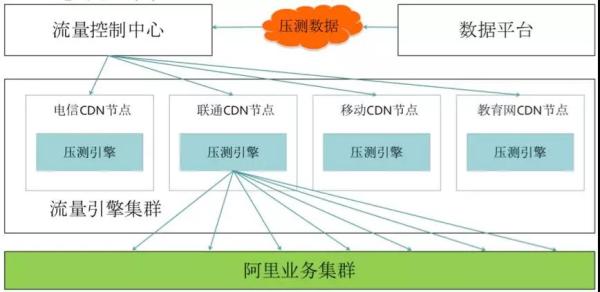
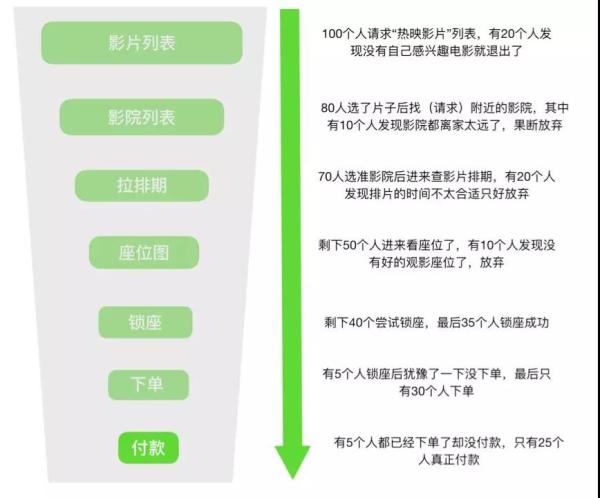
这个是阿里首创的,目前很多公司在效仿。属于是业务倒逼技术创造出来的手段。 全链路压测涉及到的内容会比较多,关键的步骤包括: 链路梳理 基础数据准备、脱敏等 中间件改造(透传影子标,软负载/消息/缓存/分库分表等路由,建立影子表) 建立压测模型、流量模型、流量引擎 预案体系的检查 执行压测,紧盯监控告警 数据清理 对业务开发团队同学来讲,关于链路梳理、流量模型的评估是其中最重要的环节,全链路压测就是模拟用户真实的访问路径构造请求,对生产环境做实际演练。 这里我以大家熟悉的购买电影票的场景为例。如下图,整个链路中业务流量其实是呈“漏斗模型”的,至于每一层的比例是多少,这个第一就是参考当前的监控,第二就是参考历史数据去推算平均值了。 漏斗模型推演示例:
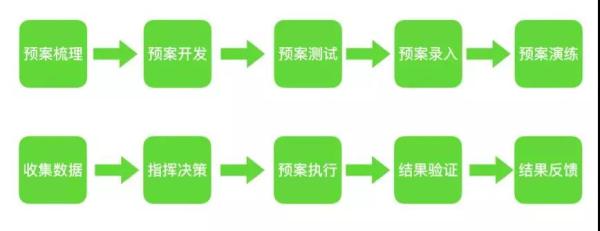
可以看出每一层(不同应用、不同服务)所需要承载的真实流量不一样,负载也是不一样的。 当然,实际场景更复杂,实际情况是多场景混合并行的,A 用户在拉排期的时候 B 用户已经在锁座了… 我们要做的,就是尽可能接近真实。还有最关键的一点要求:不能影响线上真实业务。这就需要非常强的监控告警和故障隔离能力了。 关于系统容量和水位标准,这里给大家一个建议参考值: 水位标准:单机房部署水位应在 70% 以下,双机房部署水位应在 40% 以下 单机水位:单机负载 / 单机容量 集群水位:集群负载 / 集群容量 理论机器数:实际机器数 *(集群水位 / 水位标准) 为什么双机房是 40%?一个机房故障了流量全都切到另外一个机房去,要确保整体不受影响,不会被压垮。 预案体系 电影片段中 “检查到有未知生物入侵地球,联合国宣布启动进入一级戒备,马上启动宇宙飞船达到现场” ,“已经了解清楚,并按协议执行驱逐指令,目前已经离开” … 这就是典型的预案体系。 触发条件、等级、执行动作、事后情况都非常清晰,整个过程还带有闭环的(当然这片段是我 YY 出来的)。 前面我讲过“面向失败的设计”,就是尽可能的考虑到各种异常场景和特殊情况。 这些零散的“知识点”,还有日常的一些复盘的经验都可以作为日后的预案。 当然,前面我们讲过的限流、降级等应急手段,容错模式也是整个预案体系中非常重要的。预案积累的越丰富,技术往往越成熟。 总的来讲,预案的生命周期包括:
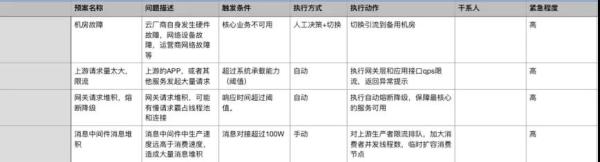
从大的层面又可以分为: 事前制定和完善预案 日常演练预案 事中统一指挥,收集数据,决策并执行预案 事后总结并继续完善和改进预案 当然,这里说明下,有些预案是达到明确的触发条件后自动执行的,有些是需要依赖人工决策然后再触发执行的。 这里我给一个简单的 Demo 给大家参考:
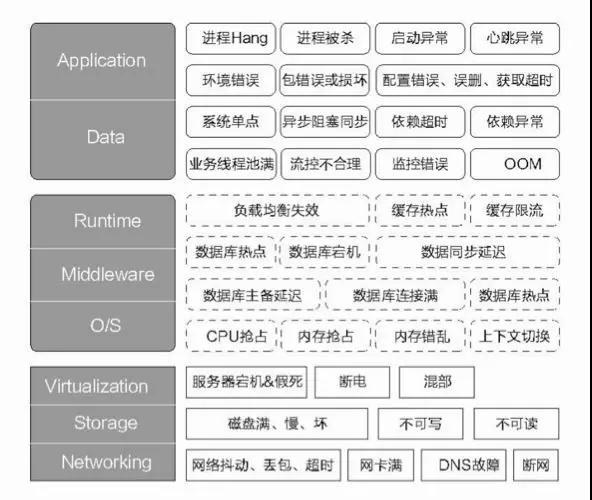
线上演练 正所谓 “养兵千日,用兵一时”。现实生活中的“消防演习”就是一个好例子,否则时间久了根本不知道灭火器放在哪里,灭火器是怎么打开的? 打开后还能喷出泡沫来吗?对应到我们技术领域也是一样的,你怎么知道你的预案都是有效的?你怎么保证 on call 值班机制没问题?你怎么知道监控告警真的很灵敏? 在阿里内部不管是大促还是常态,都会不定期来一些线上演练。在蚂蚁内部每年都会有“红蓝军对抗演练”,这是一种非常好的“以战养兵”的做法。 先看一张关于故障画像的大图,这里列举了典型的一些故障场景,大家不妨思考下如何通过“故障注入”来验证系统的高可用能力。
简单总结故障演练主要场景和目的: 预案有效性、完整性 监控告警的准确性、时效性 容灾能力测试 检查故障是否会重现 检查 on call 机制,验证突发情况团队实际战斗能力 … “混沌工程”是近年来比较流行的一种工程实践,概念由 Netflix 提出,Google、阿里在这方面的实践经验比较丰富(或者说是不谋而合,技术顶尖的公司大都很相似)。 通俗点来讲就是通过不断的给现有系统“找乱子”(进行实验),以便验证和完善现有系统的高可用性、容错性等。 引用一句鸡汤就是:“杀不死我的必将使我更强大”,混沌工程的原则:
系统成熟度模型: (编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |