阿里是如何抗住双11的?看完这篇你就明白了!
|
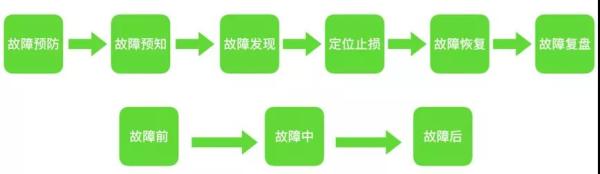
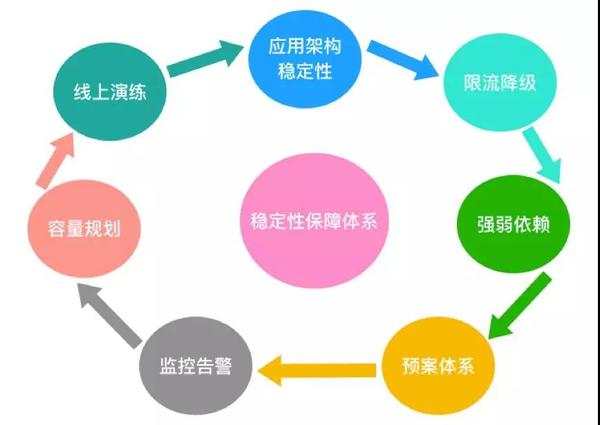
稳定性保障的核心目标如下: 尽早的预防故障,降低故障发生几率。 及时预知故障,发现定义故障。 故障将要发生时可以快速应急。 故障发生后能快速定位,及时止损,快速恢复。 故障后能够从中吸取教训,避免重复犯错。 仔细思考一下,所有的稳定性保障手段都是围绕这些目标展开的。 稳定性保障体系
上图涵盖了稳定性体系的各个方面,下面我来一一讲解。 应用架构稳定性 应用架构稳定性相对是比较广的话题,按我的理解主要包括很多设计原则和手段: ①架构设计简单化。系统架构简单清晰,易于理解,同时也需要考虑到一定的扩展性,符合软件设计中 KISS 原则。 现实中存在太多的“过度设计”和“为了技术而技术”,这些都是反例,架构师需懂得自己权衡。 ②拆分。拆分是为了降低系统的复杂度,模块或服务“自治”,符合软件设计中“单一职责”原则。拆分的太粗或者太细都会有问题,这里没有什么标准答案。 应该按照领域拆分(感兴趣同学可以学习下 DDD 中的限界上下文),结合业务复杂程度、团队规模(康威定律)等实际情况来判断。可以想象 5 个人的小团队去维护超过 30 多个系统,那一定是很痛苦的。 ③隔离。拆分本质上也是一种系统级、数据库级的隔离。此外,在应用内部也可以使用线程池隔离等。分清“主、次”,找出“高风险”的并做好隔离,可以降低发生的几率。 ④冗余。避免单点,容量冗余。机房是否单点,硬件是否单点,应用部署是否单点,数据库部署是否单点,链路是否单点…硬件和软件都是不可靠的,冗余(“备胎”)是高可用保障的常规手段。 ⑤无状态、一致性、并发控制、可靠性、幂等性、可恢复性…等。比如:投递了一个消息,如何保障消费端一定能够收到?上游重试调用了你的接口,保证数据不会重复?Redis 节点挂了分布式锁失效了怎么办?…这些都是在架构设计和功能设计中必须考虑的。 ⑥尽可能的异步化,尽可能的降低依赖。异步化某种程度可以提升性能,降低 RT,还能减少直接依赖,是常用的手段。 ⑦容错模式。 我在团队中经常强调学会“面向失败和故障的设计”,尽可能做一个“悲观主义者”,或许有些同学会不屑的认为我是“杞人忧天”,但事实证明是非常有效的。 从业以来我有幸曾在一些高手身边学习,分享受益颇多的两句话: 出来混,迟早要还的 不要心存侥幸,你担心的事情迟早要发生的
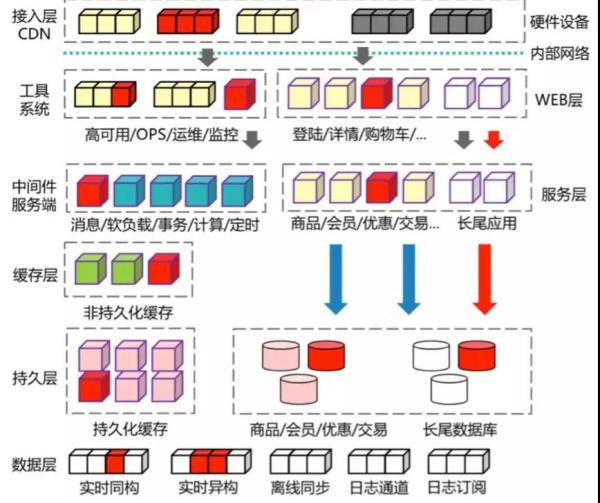
上图是比较典型的互联网分布式服务化架构,如果其中任意红色的节点出现任何问题,确定都不会影响你们系统正常运行吗? 限流降级
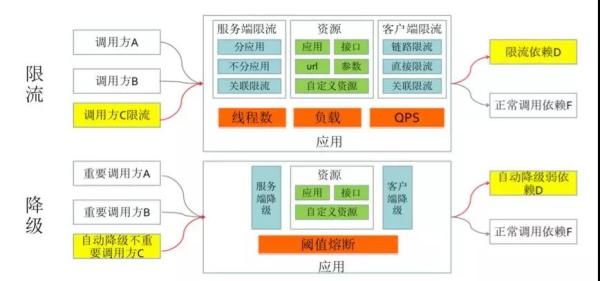
前面介绍过了限流和降级的一些场景,这里简单总结下实际使用中的一些关键点。 以限流为例,你需要先问自己并思考一些问题: 你限流的实际目的是什么?仅仅只做过载保护? 需要什么限流策略,是“单机限流”还是“集群限流”? 需要限流保护的资源有哪些?网关?应用? 水位线在哪里?限流阈值配多少? … 同理,降级你也需要考虑: 系统、接口依赖关系 哪些服务、功能可以降级掉 是使用手工降级(在动态配置中心里面加开关)还是自动熔断降级?熔断的依据是什么? 哪些服务可以执行兜底降级的?怎么去兜底(例如:挂了的时候走缓存或返回默认值)? … 这里我先卖下关子,篇幅关系,下篇文章中我会专门讲解。 监控预警
上图是我个人理解的一家成熟的互联网公司应该具备的监控体系。前面我提到过云原生时代“可观察性”,也就是监控的三大基石。 这里再简单补充一下 “健康检查”,形成经典的“监控四部曲”:
(编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |