从数据到大数据,数据技术工具的演变
|
批处理模式下的类Hadoop MapReduce的通用并行框架,Spark 与 MapReduce 不同,它将数据处理工作全部在内存中进行,提高计算性能; 流处理模式下,Spark 主要通过 Spark Streaming 实现了一种叫做微批(Micro-batch)的概念可以将数据流视作一系列非常小的“批”,借此即可通过批处理引擎的原生语义进行处理; Spark适合多样化工作负载处理任务的场景,在批处理方面适合众数吞吐率而非延迟的工作负载,SparkSQL兼容可以把Hive作为数据源spark作为计算引擎。 3)Presto 由 Facebook 开源,是一个分布式数据查询框架,原生集成了 Hive、Hbase 和关系型数据库。但背后的执行模式跟Spark类似,所有的处理都在内存中完成,大部分场景下要比 Hive 快一个数量级。 4)Kylin Cube 预计算技术是其核心,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。劣势在于每次增减维度必须对 Cube 进行历史数据重算追溯,非常消耗时间。 5)Druid 由 MetaMarket 开源,是一个分布式、面向列式存储的准实时分析数据存储系统,延迟性最细颗粒度可到 5 分钟。它能够在高并发环境下,保证海量数据查询分析性能,同时又提供海量实时数据的查询、分析与可视化功能。 7. 数据可视化模块 1)可视化框架 开源可视化框架:业界比较有名的式Superset和Metabase Superset的方案更加完善,支持聚合不同数据源形成对应的指标,再通过丰富的图表类型进行可视化,在时间序列分析上比较出色,与Druid深度集成,可快速解析大规模数据集;但不支持分组管理和图表下钻及联动功能,权限管理不友好。
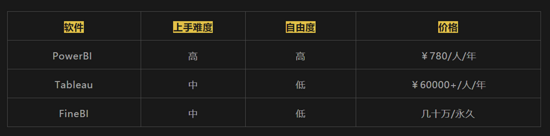
Metabase比较重视非技术人员的使用体验,界面更加美观,权限管理上做的比较完善,无需账号也可以对外共享图表和数据内容;但在时间序列分析上 不支持不同日期对比,还需要自动逸SQL实现,每次查询只能针对一个数据库,操作比较繁琐。 2)可视化软件 商用软件主流的主要有:PowerBI 、Tableau、FineBI
Tableau:操作简单,可视化,基本所有的功能都可以拖拽实现,但价格贵,且数据清洗功能一般,需要有较好的数据仓库支持 ; FineBI:操作简单,与Tableau类似,但数据清洗能力比Tableau要好,付费方式采用按功能模块收费,永久买断; PowerBI:可以做复杂报表,筛选、计算逻辑清晰,可自定义,但很多功能要用DAX编程序,托拉拽能实现的功能很有限,不易入门。
(编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |