从数据到大数据,数据技术工具的演变
|
如果还不理解的话我们举个栗子:假期要结束了张三还有有10份作业没写,他找了5个同学,每个同学写2份,最后汇总给张三。
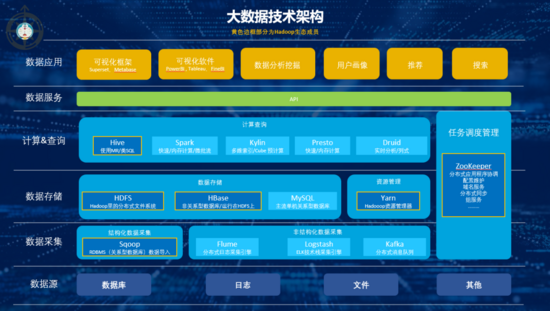
大数据时代存储计算的经典模型,Apache基金会名下的Hadhoop系统,核心就是采用的分布式计算架构,也是Yahoo、IBM、Facebook、亚马逊、阿里巴巴、华为、百度、腾讯等公司,都采用技术架构(下方逻辑图中黄框部分都是Hadoop生态的成员)。 3. 大数据架构与模块主要有哪些?
大数据架构主要可以分为:数据采集,数据存储,计算查询,数据服务,数据应用5个环节。 1)数据采集 通过采集工具把结构化数据进行采集、分发、校验、清洗转换;非结构化数据通过爬取,分词,信息抽取,文本分类,存入数据仓库中。 2)数据存储 一般分3层,最底层的式ODS(操作数据)层,直接存放业务系统抽取过来的数据,将不同业务系统中的数据汇聚在一起;中间是DW(数据仓库)层,存放按照主题建立的各种数据模型;最上层是DM(数据集市)层,基于DW层上的基础数据整合汇总成分析某一个主题域的报表数据。 3)计算查询 根据具体的需求选择对应的解决方案:离线、非实时、静态数据的可以用批处理方案;非离线、实时、动态数据、低延迟的场景可用流处理方案。 4)数据服务 通过API把数仓中海量的数据高效便捷的开放出去支撑业务,发挥数据价值。 5)数据应用 基于数据仓库中结构清晰的数据高效的构建BI系统支撑业务决策;根据海量的数据构建以标签树为核心的用户画像系统,为个性化推荐、搜索等业务模块提供支撑。 4. 大数据采集模块
一般应用于公司日志平台,将数据缓存在某个地方,供后续的计算流程进行使用 针对不同数据源(APP,服务器,日志,业务表,各种API接口,数据文件……)有各自的采集方式。 目前市面上针对日志采集的有 Flume、Logstash、Kafka…… 1)Flume 是一款 Cloudera 开发的实时采集日志引擎,主打高并发、高速度、分布式海量日志采集,支持在日志系统中定制各类数据发送,支持对数据简单处理并写给各种数据接受方,主要特点: 侧重数据传输,有内部机制确保不会丢数据,用于重要日志场景; 由java开发,没有丰富的插件,主要靠二次开发; 配置繁琐,对外暴露监控端口有数据。最初定位是把数据传入HDFS中,跟侧重于数据传输和安全,需要更多二次开发配置。 2)Logstash 是 Elastic旗下的一个开源数据收集引擎,可动态的统一不同的数据源的数据至目的地,搭配 ElasticSearch 进行分析,Kibana 进行页面展示,主要特点: 内部没有一个persist queue(存留队列),异常情况可能会丢失部分数据; 由ruby编写,需要ruby环境,插件很多; 配置简单,偏重数据前期处理,分析方便 侧重对日志数据进行预处理为后续解析做铺垫,搭配ELK技术栈使用简单。 3)Kafka 最初是由领英开发,2012 年开源由Apache Incubato孵化出站。以为处理实时数据提供一个统一、高吞吐、低延迟的平台,适合作为企业级基础设施来处理流式数据 (本质是:按照分布式事务日志架构的大规模发布/订阅消息队列)。 4)Sqoop 与上面的日志采集工具不同,Sqoop的主要功能是为 Hadoop 提供了方便的 RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向 HBase 中迁移变的非常方便。 5. 大数据存储&资源管理模块
在数据量小的时候一般用单机数据库(如:MySQL) 但当数据量大到一定程度就必须采用分布式系统了,Apache基金会名下的Hadhoop系统是大数据时代存储计算的经典模型。 1)HDFS 是 Hadoop里的分布式文件系统,为HBase 和 Hive提供了高可靠性的底层存储支持。 2)HBase 是Hadoop数据库,作为基于非关系型数据库运行在HDFS上,具备HDFS缺乏的随机读写能力,比较适合实时分析。 3)Yarn 是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。 6. 大数据计算查询模块 这里首先要介绍一下批处理和流处理的区别: 批计算:离线场景、静态数据、非实时、高延迟(场景:数据分析,离线报表……) 流计算:实时场景,动态数据,实时,低延迟(场景:实时推荐,业务监控……) 大数据常用的计算查询引擎主要有:Hive、Spark、Presto、Presto、Kylin、Druid……
1)Hive 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行,其优点是学习成本低。 2)Spark Spark是加州大学伯克利分校AMP实验室所开源的专门用于大数据量下的迭代式计算,是为了跟 Hadoop 配合: (编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |