从未如此简单:10分钟带你逆袭Kafka!
|
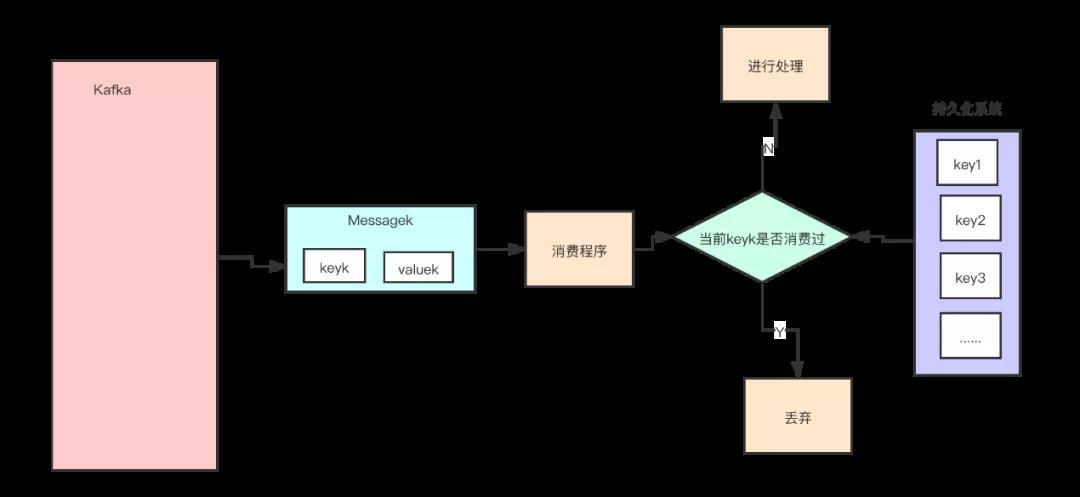
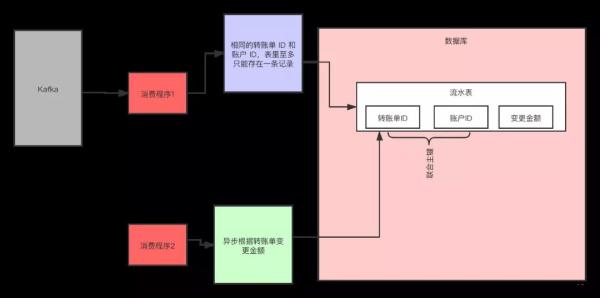
方案二:利用幂等 幂等(Idempotence)在数学上是这样定义的,如果一个函数 f(x) 满足:f(f(x)) = f(x),则函数 f(x) 满足幂等性。 这个概念被拓展到计算机领域,被用来描述一个操作、方法或者服务。一个幂等操作的特点是,其任意多次执行所产生的影响均与一次执行的影响相同。 一个幂等的方法,使用同样的参数,对它进行多次调用和一次调用,对系统产生的影响是一样的。所以,对于幂等的方法,不用担心重复执行会对系统造成任何改变。 我们举个例子来说明一下。在不考虑并发的情况下,“将 X 老师的账户余额设置为 100 万元”,执行一次后对系统的影响是,X 老师的账户余额变成了 100 万元。 只要提供的参数 100 万元不变,那即使再执行多少次,X 老师的账户余额始终都是 100 万元,不会变化,这个操作就是一个幂等的操作。 再举一个例子,“将 X 老师的余额加 100 万元”,这个操作它就不是幂等的,每执行一次,账户余额就会增加 100 万元,执行多次和执行一次对系统的影响(也就是账户的余额)是不一样的。 所以,通过这两个例子,我们可以想到如果系统消费消息的业务逻辑具备幂等性,那就不用担心消息重复的问题了,因为同一条消息,消费一次和消费多次对系统的影响是完全一样的。也就可以认为,消费多次等于消费一次。 那么,如何实现幂等操作呢?最好的方式就是,从业务逻辑设计上入手,将消费的业务逻辑设计成具备幂等性的操作。 但是,不是所有的业务都能设计成天然幂等的,这里就需要一些方法和技巧来实现幂等。 下面我们介绍一种常用的方法:利用数据库的唯一约束实现幂等。 例如,我们刚刚提到的那个不具备幂等特性的转账的例子:将 X 老师的账户余额加 100 万元。在这个例子中,我们可以通过改造业务逻辑,让它具备幂等性。 首先,我们可以限定,对于每个转账单每个账户只可以执行一次变更操作,在分布式系统中,这个限制实现的方法非常多,最简单的是我们在数据库中建一张转账流水表。 这个表有三个字段:转账单 ID、账户 ID 和变更金额,然后给转账单 ID 和账户 ID 这两个字段联合起来创建一个唯一约束,这样对于相同的转账单 ID 和账户 ID,表里至多只能存在一条记录。 这样,我们消费消息的逻辑可以变为:“在转账流水表中增加一条转账记录,然后再根据转账记录,异步操作更新用户余额即可。” 在转账流水表增加一条转账记录这个操作中,由于我们在这个表中预先定义了“账户 ID 转账单 ID”的唯一约束,对于同一个转账单同一个账户只能插入一条记录,后续重复的插入操作都会失败,这样就实现了一个幂等的操作。
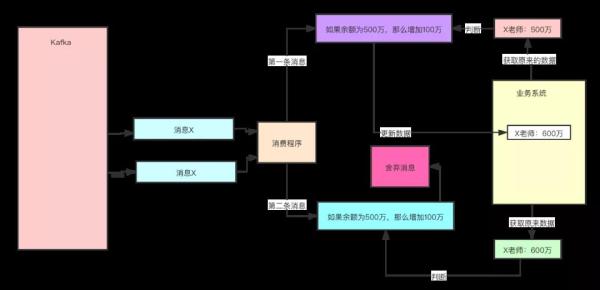
方案三:设置前提条件 为更新的数据设置前置条件另外一种实现幂等的思路是,给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。 这样,重复执行这个操作时,由于第一次更新数据的时候已经变更了前置条件中需要判断的数据,不满足前置条件,则不会重复执行更新数据操作。 比如,刚刚我们说过,“将 X 老师的账户的余额增加 100 万元”这个操作并不满足幂等性,我们可以把这个操作加上一个前置条件,变为:“如果 X 老师的账户当前的余额为 500 万元,将余额加 100 万元”,这个操作就具备了幂等性。 对应到消息队列中的使用时,可以在发消息时在消息体中带上当前的余额,在消费的时候进行判断数据库中,当前余额是否与消息中的余额相等,只有相等才执行变更操作。 但是,如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢? 更加通用的方法是,给你的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等。
Kafka 集群搭建 我们在工作中,为了保证环境的高可用,防止单点,Kafka 都是以集群的方式出现的,下面就带领大家一起搭建一套 Kafka 集群环境。 我们在官网下载 Kafka,下载地址为:,下载我们需要的版本,推荐使用稳定的版本。 搭建集群 ①下载并解压 cd /usr/local/src wget mkdir /data/servers tar xzvf kafka_2.11-2.4.0.tgz -C /data/servers/ cd /data/servers/kafka_2.11-2.4.0 ②修改配置文件 Kafka 的配置文件 $KAFKA_HOME/config/server.properties,主要修改一下下面几项: 确保每个机器上的id不一样 broker.id=0 配置服务端的监控地址 listeners=PLAINTEXT://192.168.51.128:9092 kafka 日志目录 log.dirs=/data/servers/kafka_2.11-2.4.0/logs #kafka设置的partitons的个数 num.partitions=1
zookeeper的连接地址, 如果有自己的zookeeper集群, 请直接使用自己搭建的zookeeper集群 zookeeper.connect=192.168.51.128:2181 因为我自己是本机做实验,所有使用的是一个主机的不同端口,在线上,就是不同的机器,大家参考即可。 我们这里使用 Kafka 的 Zookeeper,只启动一个节点,但是正真的生产过程中,是需要 Zookeeper 集群,自己搭建就好,后期我们也会出 Zookeeper 的教程,大家请关注就好了。 ③拷贝 3 份配置文件 #创建对应的日志目录 mkdir -p /data/servers/kafka_2.11-2.4.0/logs/9092 mkdir -p /data/servers/kafka_2.11-2.4.0/logs/9093 mkdir -p /data/servers/kafka_2.11-2.4.0/logs/9094
#拷贝三份配置文件 cp server.properties server_9092.properties cp server.properties server_9093.properties cp server.properties server_9094.properties ④修改不同端口对应的文件 #9092的id为0, 9093的id为1, 9094的id为2 broker.id=0 # 配置服务端的监控地址, 分别在不通的配置文件中写入不同的端口 listeners=PLAINTEXT://192.168.51.128:9092 # kafka 日志目录, 目录也是对应不同的端口 log.dirs=/data/servers/kafka_2.11-2.4.0/logs/9092 # kafka设置的partitons的个数 num.partitions=1 # zookeeper的连接地址, 如果有自己的zookeeper集群, 请直接使用自己搭建的zookeeper集群 zookeeper.connect=192.168.51.128:2181 修改 Zookeeper 的配置文件: dataDir=/data/servers/zookeeper server.1=192.168.51.128:2888:3888 然后创建 Zookeeper 的 myid 文件: echo "1"> /data/servers/zookeeper/myid ⑤启动 Zookeeper 使用 Kafka 内置的 Zookeeper: cd /data/servers/kafka_2.11-2.4.0/bin zookeeper-server-start.sh -daemon ../config/zookeeper.properties netstat -anp |grep 2181 启动 Kafka: ./kafka-server-start.sh -daemon ../config/server_9092.properties ./kafka-server-start.sh -daemon ../config/server_9093.properties ./kafka-server-start.sh -daemon ../config/server_9094.properties Kafka 的操作 ①Topic 我们先来看一下创建 Topic 常用的参数吧: --create:创建 topic --delete:删除 topic --alter:修改 topic 的名字或者 partition 个数 --list:查看 topic --describe:查看 topic 的详细信息 --topic --zookeeper 示例: cd /data/servers/kafka_2.11-2.4.0/bin # 创建topic test1 (编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |