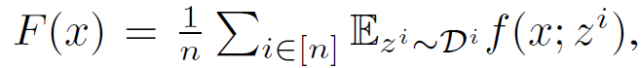当传统联邦学习面临异构性挑战,不妨尝试这些个性化联邦学习算法
|
本文选择了三篇关于个性化联邦学习的文章进行深入分析。 经典的机器学习方法基于样本数据(库)训练得到适用于不同任务和场景的机器学习模型。这些样本数据(库)一般通过从不同用户、终端、系统中收集并集中存储而得到。在实际应用场景中,这种收集样本数据的方式面临很多问题。一方面,这种方法损害了数据的隐私性和安全性。在一些应用场景中,例如金融行业、政府行业等,受限于数据隐私和安全的要求,根本无法实现对数据的集中存储;另一方面,这种方法会增加通信开销。在物联网等一些大量依赖于移动终端的应用中,这种数据汇聚的通信开销成本是非常巨大的。 联邦学习允许多个用户(称为客户机)协作训练共享的全局模型,而无需分享本地设备中的数据。由中央服务器协调完成多轮联邦学习以得到最终的全局模型。其中,在每一轮开始时,中央服务器将当前的全局模型发送给参与联邦学习的客户机。每个客户机根据其本地数据训练所接收到的全局模型,训练完毕后将更新后的模型返回中央服务器。中央服务器收集到所有客户机返回的更新后,对全局模型进行一次更新,进而结束本轮更新。通过上述多轮学习和通信的方法,联邦学习消除了在单个设备上聚合所有数据的需要,克服了机器学习任务中的隐私和通信挑战,允许机器学习模型学习分散在各个用户(客户机)上存储的数据。 联邦学习自提出以来获得了广泛的关注,并在一些场景中得以应用。联邦学习解决了数据汇聚的问题,使得一些跨机构、跨部门的机器学习模型、算法的设计和训练成为了可能。特别地,对于移动设备中的机器学习模型应用,联邦学习表现出了良好的性能和鲁棒性。此外,对于一些没有足够的私人数据来开发精确的本地模型的用户(客户机)来说,通过联邦学习能够大大改进机器学习模型和算法的性能。但是,由于联邦学习侧重于通过分布式学习所有参与客户机(设备)的本地数据来获得高质量的全局模型,因此它无法捕获每个设备的个人信息,从而导致推理或分类的性能下降。此外,传统的联邦学习需要所有参与设备就协作训练的共同模型达成一致,这在实际复杂的物联网应用中是不现实的。研究人员将联邦学习在实际应用中面临的问题总结如下[2]:(1)各个客户机(设备)在存储、计算和通信能力方面存在异构性;(2) 各个客户机(设备)本地数据的非独立同分布(Non-Idependently and Identically Distributed,Non-IID)所导致的数据异构性问题;(3)各个客户机根据其应用场景所需要的模型异构性问题。 为了解决这些异构性挑战,一种有效的方法是在设备、数据和模型级别上进行个性化处理,以减轻异构性并为每个设备获得高质量的个性化模型,即个性化联邦学习(Personalized Federated Learning)。针对 Non-IID 的联邦学习,机器之心之前有专门的分析文章,感兴趣的读者可以阅读。针对设备异构性的问题,一般可以通过设计新的分布式架构(如 Client-Edge-Cloud[5])或新的联邦学习算法( Asynchronous Fed[6])来解决。 针对模型异构性的问题,作者在文献 [1] 中将不同的个性化联邦学习方法分为以下几类:增加用户上下文(Adding User Context )[8]、迁移学习(Transfer Learning)[9]、多任务学习(Multi-task Learning)[10]、元学习(Meta-Learning)[3]、知识蒸馏(Knowledge Distillation )[11]、基本层 + 个性化层( Base + Personalization Layers)[4]、混合全局和局部模型(Mixture of Global and Local Models )[12] 等。 本文选择了三篇关于个性化联邦学习的文章进行深入分析。其中,第一篇文章关于设备异构性的问题[6],作者提出了一种新的异步联邦优化算法。对于强凸和非强凸问题以及一类受限的非凸问题,该方法能够近似线性收敛到全局最优解。第二篇文章重点解决模型异构性的问题[7],作者提出了一种引入 Moreau Envelopes 作为客户机正则化损失函数的个性化联邦学习算法(pFedMe),该算法有助于将个性化模型优化与全局模型学习分离开来。最后,第三篇文章提出了一个协同云边缘框架 PerFit,用于个性化联邦学习,从整体上缓解物联网应用中固有的设备异构性、数据异构性和模型异构性[2]。 一、Asynchronous Federated Optimization
随着边缘设备 / 物联网(如智能手机、可穿戴设备、传感器以及智能家居 / 建筑)的广泛使用,这些设备在人们日常生活中所产生的大量数据催生了 “联邦学习” 的方法。另一方面,对于人工智能算法中所使用的的样本数据隐私性的考虑,进一步提高了人们对联邦学习的关注度。然而,联邦学习是同步优化(Synchronous)的,即中央服务器将全局模型同步发送给多个客户机,多个客户机基于本地数据训练模型后同步将更新后的模型返回中央服务器。联邦学习的同步特性具有不可扩展、低效和不灵活等问题。这种同步学习的方法在接入大量客户机的情况下,存在同时接收太多设备反馈会导致中央服务器端网络拥塞的问题。此外,由于客户机的计算能力和电池时间有限,任务调度因设备而异,因此很难在每个更新轮次(epoch)结束时精准的同步接入的客户机。传统方法会采取设定超时阈值的方法,删除无法及时同步的客户机。但是,如果可接入同步的客户机数量太少,中央服务器可能不得不放弃整个 epoch,包括所有已经接收到的更新。 为了解决同步联邦学习中出现的这些问题,本文提出了一种新的异步联邦优化算法,其关键思想是使用加权平均值来更新全局模型。可以根据陈旧性函数(A Function of the Staleness)自适应设定混合权重值。作者在文中证明,这些更改结合在一起能够生成有效的异步联邦优化过程。 1.1 方法介绍 给定 n 个客户机,经典联邦学习表示为:
其中,z^i 为第 i 个客户机设备中的数据采样。由于不同的客户机设备之间存在异构性,所存储的数据库也不同,从不同设备中提取的样本具有不同的期望值: 联邦学习的一次完整的更新过程由 T 个全局 epochs 组成。在第 t 个 epoch 中,中央服务器接收任意一个客户机发回的本地训练的模型 x_new,并通过加权平均来更新全局模型: 其中,α∈(0,1),α为混合超参数 (mixing hyperparameter)。在任意设备 i 上,在从中央服务器接收到全局模型 x_t(可能已经过时)后,使用 SGD 进行局部优化以解决以下正则化优化问题: (编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |