�����ʡ��ֿ�ֱ����ˣ����ʾͱ����ˣ�
|
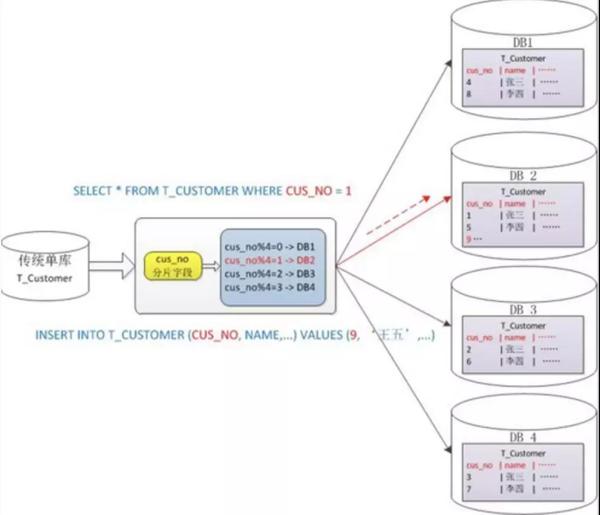
�������ٿ��Ƭ��ѯ�ĸ������⡣���������У����Ƶ���õ��IJ�ѯ�����в��� cusno ʱ�����ᵼ������λ���ݿ⣬�Ӷ���Ҫͬʱ�� 4 ���ⷢ���ѯ�������ڴ��кϲ����ݣ�ȡ��С�����ظ�Ӧ�ã��ֿⷴ����Ϊ���ۡ�
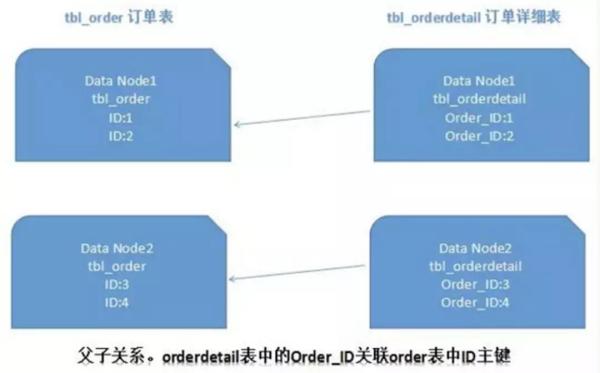
�ֿ�ֱ����������� �ֿ�ֱ�����Ч�Ļ��ⵥ���͵������������ƿ����ѹ����ͻ������ IO��Ӳ����Դ����������ƿ����ͬʱҲ������һЩ���⡣���潫������Щ������ս�Լ���Ӧ�Ľ��˼·�� ����һ�������� �ٷֲ�ʽ���� ����������ͬʱ�ֲ��ڲ�ͬ���У����ɱ�����������������⡣���Ƭ����Ҳ�Ƿֲ�ʽ����û�мķ�����һ���ʹ��"XA Э��"��"�����ύ"������ �ֲ�ʽ����������ȱ�֤�����ݿ������ԭ���ԡ������ύ����ʱ��ҪЭ������ڵ㣬�ƺ����ύ�����ʱ��㣬�ӳ��������ִ��ʱ�䡣���������ڷ��ʹ�����Դʱ������ͻ�������ĸ������ߡ� �������ݿ�ڵ�����࣬�������ƻ�Խ��Խ���أ��Ӷ���Ϊϵͳ�����ݿ������ˮƽ��չ�ļ����� ������һ���� ������Щ����Ҫ��ܸߣ�����һ����Ҫ�ߵ�ϵͳ������������ϵͳ��ʵʱһ���ԣ�ֻҪ��������ʱ����ڴﵽ����һ���Լ��ɣ��ɲ��������ķ�ʽ�� ��������ִ���з�������������ع��ķ�ʽ��ͬ��������һ���º��鲹�ȵĴ�ʩ�� һЩ������ʵ�ַ����У������ݽ��ж��˼�飬������־���жԱȣ�����ͬ��������Դ����ͬ���ȵȡ�������Ҫ���ҵ��ϵͳ�����ǡ� ��ڵ������ѯ join ���� �з�֮ǰ��ϵͳ�кܶ��б�������ҳ��������ݿ���ͨ�� sql join ����ɡ� ���з�֮�����ݿ��ֲܷ��ڲ�ͬ�Ľڵ��ϣ���ʱ join ����������ͱȽ��鷳�ˣ����ǵ����ܣ���������ʹ�� join ��ѯ�� �����������һЩ������ ��ȫ�ֱ���ȫ�ֱ���Ҳ�ɿ�����"�����ֵ��"������ϵͳ������ģ�鶼����������һЩ����Ϊ�˱����� join ��ѯ�����Խ��������ÿ�����ݿ��ж�����һ�ݡ���Щ����ͨ�����ٻ�����ģ�����Ҳ������һ���Ե����⡣ ���ֶ�������һ�ֵ��͵ķ���ʽ��ƣ����ÿռ任ʱ�䣬Ϊ�����ܶ����� join ��ѯ�� ���磺���������� userId ʱ��Ҳ�� userName ���ౣ��һ�ݣ�������ѯ��������ʱ�Ͳ���Ҫ��ȥ��ѯ"��� user ��"�ˡ� �����ַ������ó���Ҳ���ޣ��Ƚ������������ֶαȽ��ٵ�������������ֶε�����һ����Ҳ���ѱ�֤���������涩���������ӣ�������� userName ���Ƿ���Ҫ����ʷ������ͬ��������?��ҲҪ���ʵ��ҵ�����п��ǡ� ��������װ����ϵͳ���棬�����β�ѯ����һ�β�ѯ�Ľ�������ҳ��������� id��Ȼ����� id ����ڶ�������õ��������ݡ����õ������ݽ����ֶ�ƴװ�� ��ER ��Ƭ����ϵ�����ݿ��У����������ȷ����֮��Ĺ�����ϵ��������Щ���ڹ�����ϵ�ı���¼�����ͬһ����Ƭ�ϣ���ô���ܽϺõı�����Ƭ join ���⡣�� 1:1 �� 1:n ������£�ͨ������������ ID �����з֡� ����ͼ��ʾ��
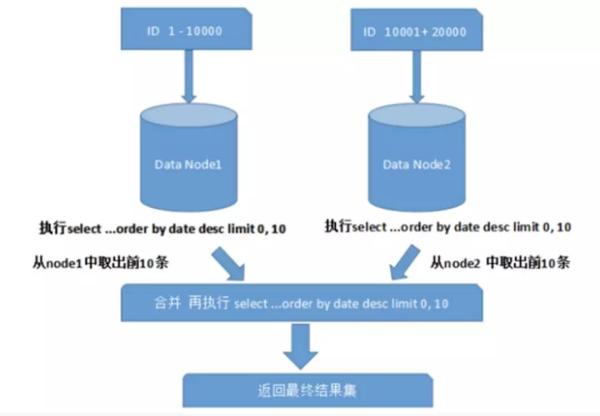
����һ����Data Node1 ����� order �������� orderdetail ����������Ϳ���ͨ�� orderId ���оֲ��Ĺ�����ѯ�ˣ�Data Node2 ��Ҳһ���� ��ڵ��ҳ������������ ��ڵ�����в�ѯʱ������� limit ��ҳ��order by ��������⡣��ҳ��Ҫ����ָ���ֶν������������ֶξ��Ƿ�Ƭ�ֶ�ʱ��ͨ����Ƭ����ͱȽ�����λ��ָ���ķ�Ƭ;�������ֶηǷ�Ƭ�ֶ�ʱ���ͱ�ñȽϸ����ˡ� ��Ҫ���ڲ�ͬ�ķ�Ƭ�ڵ��н����ݽ��������أ�Ȼ��ͬ��Ƭ���صĽ�������л��ܺ��ٴ��������շ��ظ��û��� ��ͼ��ʾ��
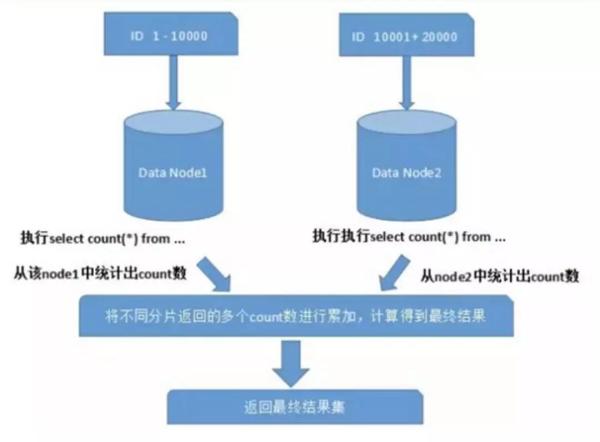
��ͼ��ֻ��ȡ��һҳ�����ݣ�������Ӱ�컹���Ǻܴ������ȡ��ҳ���ܴ�������ø��Ӻܶࡣ ��Ϊ����Ƭ�ڵ��е����ݿ���������ģ�Ϊ�������ȷ�ԣ���Ҫ�����нڵ��ǰ N ҳ���ݶ���������ϲ�������ٽ�����������������IJ����Ǻܺķ� CPU ���ڴ���Դ�ģ�����ҳ��Խ��ϵͳ������Ҳ��Խ� ��ʹ�� Max��Min��Sum��Count ֮��ĺ������м����ʱ��Ҳ��Ҫ����ÿ����Ƭ��ִ����Ӧ�ĺ�����Ȼ������Ƭ�Ľ�������л��ܺ��ٴμ��㣬���ս�������ء� ��ͼ��ʾ��
ȫ�������������� �ڷֿ�ֱ������У����ڱ�������ͬʱ���ڲ�ͬ���ݿ��У�����ֵƽʱʹ�õ���������������֮�أ�ij���������ݿ������ɵ� ID ����֤ȫ��Ψһ�� �����Ҫ�������ȫ���������Ա����������ظ����⡣��һЩ�������������ɲ��ԣ� ��UUID UUID ����ʽ���� 32 �� 16 �������֣���Ϊ 5 �Σ���ʽΪ 8-4-4-4-12 �� 36 ���ַ������磺550e8400-e29b-41d4-a716-446655440000�� UUID ����������ķ������������ɣ����ܸߣ�û�������ʱ����ȱ��Ҳ�����ԣ����� UUID �dz�������ռ�ô����Ĵ洢�ռ䡣 ���⣬��Ϊ�������������ͻ����������в�ѯʱ��������������⣬�� InnoDB �£�UUID �������Ի���������λ��Ƶ���䶯�����·�ҳ�� �ڽ�����ݿ�ά������ ID �� �����ݿ��н��� sequence ���� CREATE TABLE `sequence` ( `id` bigint(20) unsigned NOT NULL auto_increment, ���༭��Ӧ����_����վ������ ����������վ���ݾ��������磬��������۽��������߸��˹۵㣬��������վ�������������ַ�������Ȩ�����뼰ʱ����ϵվ��ɾ���������! |