详解GPU技术关键参数和应用场景
|
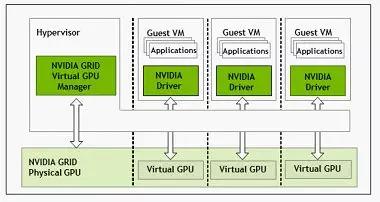
Quadro系列:主要面向专业图形工作站应用,具备强大的数据运算与图形、图像处理能力。因此常常被用在计算机辅助设计及制造CAD/CAM、动画设计、科学研究(城市规划、地理地质勘测、遥感等)、平面图像处理、模拟仿真等。 GPU加速计算Tesla系列:专用GPU加速计算,Tesla本是第一代产品的架构名称,后来演变成了这个系列产品的名称了,包括V100、P100、K40/K80、M40/M60等几个型号。K系列更适合用作HPC科学计算,M系列则更适合机器学习用途。 Tesla系列高端型号GPU加速器能更快地处理要求超级严格的 HPC 与超大规模数据中心的工作负载。从能源探测到深度学习等应用场合,处理速度比使用传统 CPU 快了一个数量级。 GPU虚拟化系列:Nvidia专门针对虚拟化环境应用设计GRID GPU产品,该产品采用基于 NVIDIA Kepler 架构的 GPU,首次实现了 GPU 的硬件虚拟化。这意味着,多名用户可以共享单一 GPU。
GRID GPU产品主要包含K1和K2两个型号,同样采用Kepler架构,实现了GPU的硬件虚拟化,可以让多个用户共享使用同一张GPU卡,适用于对3D性能有要求的VDI或云环境下多租户的GPU加速计算场景。 GPU散热方式分为散热片和散热片配合风扇的形式,也叫作主动式散热和被动式散热方式。 一般一些工作频率较低的显卡采用的都是被动式散热,这种散热方式就是在显示芯片上安装一个散热片即可,并不需要散热风扇。因为较低工作频率的显卡散热量并不是很大,没有必要使用散热风扇,这样在保障显卡稳定工作的同时,不仅可以降低成本,而且还能减少使用中的噪音。 NVIDIA Tesla Family采用被动散热、QUADRO Family和GeForce Family采用主动散热。 NVIDIA GPU架构的发展类似Intel的CPU,针对不同场景和技术革新,经历了不同架构的演进。 Turing架构里,一个SM中拥有64个半精度,64个单精度,8个Tensor core,1个RT core。 Kepler架构里,FP64单元和FP32单元的比例是1:3或者1:24;K80。 Maxwell架构里,这个比例下降到了只有1:32;型号M10/M40。 Pascal架构里,这个比例又提高到了1:2(P100)但低端型号里仍然保持为1:32,型号Tesla P40、GTX 1080TI/Titan XP、Quadro GP100/P6000/P5000 Votal架构里,FP64单元和FP32单元的比例是1:2;型号有Tesla V100、GeForce TiTan V、Quadro GV100专业卡。
深度学习是模拟人脑神经系统而建立的数学网络模型,这个模型的最大特点是,需要大数据来训练。因此,对电脑处理器的要求,就是需要大量的并行的重复计算,GPU正好有这个专长,时势造英雄,因此,GPU就出山担当重任了。 训练:我们可以把深度学习的训练看成学习过程。人工神经网络是分层的、是在层与层之间互相连接的、网络中数据的传播是有向的。训练神经网络的时候,训练数据被输入到网络的第一层。然后所有的神经元,都会根据任务执行的情况,根据其正确或者错误的程度如何,分配一个权重参数(权值)。 推理:就是深度学习把从训练中学习到的能力应用到工作中去。不难想象,没有训练就没法实现推断。我们人也是这样,通过学习来获取知识、提高能力。深度神经网络也是一样,训练完成后,并不需要其训练时那样的海量资源。 高性能计算应用程序涵盖了物理、生物科学、分子动力学、化学和天气预报等各个领域。也都是通过GPU实现加速的。 (编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |