深2.5至4倍,参数和计算量更少,DeLighT怎么做到的?
|
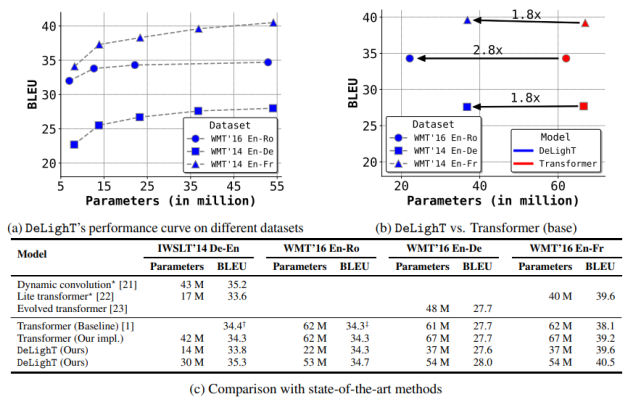
为此,该研究提出两个配置参数:DeLighT 网络中 DExTra 的最小深度 N_min 和最大深度 N_max。然后,使用线性缩放(公式 4)计算每个 DeLighT 块 b 中 DExTra 的深度 N^b 和宽度乘数 m^b_w。通过这种缩放,每个 DeLighT 块 b 都有不同的深度和宽度(图 2a)。 实验结果 该论文在两个常见的序列建模任务(机器翻译和语言建模)上进行了性能比较。 机器翻译 该研究对比了 DeLighT 和当前最优方法(标准 transformer [1]、动态卷积 [21] 和 lite transformer [22])在机器翻译语料库上的性能,如下图 3 所示。图 3c 表明,DeLighT 提供了最优的性能,在参数和计算量较少的情况下性能优于其他模型。
图 3:模型在机器翻译语料库上的结果。与标准 transformers 相比,DeLighT 模型用更少的参数就能达到类似的性能。图中 † 和 ‡ 分别表示来自 [21] 和 [48] 的最优 transformer 基线。
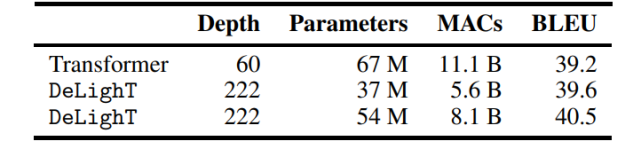
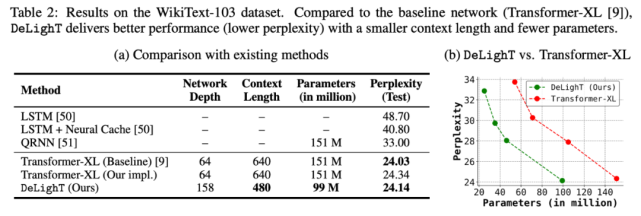
表 1:在 WMT’14 En-Fr 数据集上,机器翻译模型在网络深度、网络参数、MAC 数量和 BLEU 值方面的对比结果。DeLighT 表现最优异,在网络深度较深的情况下,参数量和运算量都更少。 语言建模 该研究在 WikiText-103 数据集上,对 DeLighT 和其他方法的性能进行了对比(如表 2a 所示)。表 2b 则绘制了 DeLighT 和 Transformer-XL [9] 的困惑度随参数量的变化情况。这两个表都表明,DeLighT 优于当前最优的方法(包括 Transformer-XL),而且它使用更小的上下文长度和更少的参数实现了这一点,这表明使用 DeLighT 学得的更深且宽的表示有助于建模强大的上下文关系。
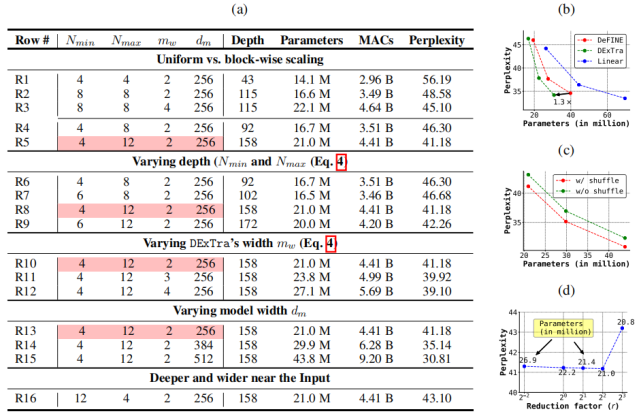
控制变量研究 表 3a 研究了 DeLighT 块参数的影响,这些参数分别是网络最小深度 N_min、最大深度 N_max、宽度乘法 m_w 和模型维度 d_m(见图 1d)。表 3b-d 分别展示了 DExTra 变换、特征 shuffling 和轻量级 FFN 的影响。
总结 该研究提出了一种非常轻巧但深度较大的 transformer 框架——DeLighT,该框架可在 DeLighT 块内以及对所有 DeLighT 块高效分配参数。与当前最优的 Transformer 模型相比,DeLighT 模型具备以下优点:1)非常深且轻量级;2)提供相似或更好的性能。
(编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |