清华开源迁移学习算法库:基于PyTorch实现,支持轻松调用已有算法
|
近日,清华大学大数据研究中心机器学习研究部开源了一个高效、简洁的迁移学习算法库 Transfer-Learn,并发布了第一个子库——深度领域自适应算法库(DALIB)。 清华大学大数据研究中心机器学习研究部长期致力于迁移学习研究。近日,该课题部开源了一个基于 PyTorch 实现的高效简洁迁移学习算法库:Transfer-Learn。使用该库,可以轻松开发新算法,或使用现有算法。
项目地址:https://github.com/thuml/Transfer-Learning-Library 目前,该项目发布了第一个子库——领域自适应算法库(DALIB),其支持的算法包括: Domain Adversarial Neural Network (DANN) Deep Adaptation Network (DAN) Joint Adaptation Network (JAN) Conditional Domain Adversarial Network (CDAN) Maximum Classifier Discrepancy (MCD) Margin Disparity Discrepancy (MDD) 领域自适应背景介绍 目前,深度学习模型在一部分计算机视觉、自然语言处理任务中超越了人类的表现,但是它们的成功通常依赖于大规模标记数据。在实际应用场景中,标记数据往往是稀缺的。 解决标记数据稀缺问题的一个方法是通过计算机模拟生成训练数据,例如使用计算机图形学技术合成训练数据(如下图所示)。此外,还可以从相关的领域 “借用” 标记数据。
但是,在此场景下,训练数据和测试数据不再服从独立同分布,使训练得到的深度网络准确率大打折扣。为了解决数据集偏移造成的泛化难题,领域自适应 (Domain Adaptation) 的概念被提出。 领域自适应的目标是将机器学习模型在源领域 (Source) 学到的知识迁移到目标领域 (Target)。例如在计算机模拟生成训练数据的例子中,合成数据是源领域,真实场景的数据是目标领域。领域自适应有效地缓解了深度学习对于人工标记数据的依赖,受到学术界和工业界的广泛关注。目前已广泛应用到图像分类、图像分割、目标检测、情感分析、机器翻译等众多任务上。 吴恩达曾说过:「在监督学习之后,迁移学习将引领下一轮机器学习技术商业化浪潮。」图灵奖得主 Bengio 也认为迁移能力是深度学习进一步发展的基础能力之一。随着产品级机器学习应用进入数据稀缺领域,监督学习得到的尖端模型性能大打折扣,领域自适应变得越来越重要。 研究现状 深度领域自适应方法主要包括以下三大类: 统计距离。通过最小化源领域和目标领域分布的统计距离,实现不同领域特征分布对齐。例如深度适配网络 DAN、联合适配网络 JAN。 对抗训练。领域对抗网络 DANN 是最早的工作,它引入领域判别器,鼓励特征提取器学习领域无关的特征。在 DANN 的基础上衍生出了一系列方法,例如条件领域对抗网络 CDAN、最大分类器差异 MCD。 理论启发。通过严格的理论推导,得到可以显式控制迁移学习泛化误差的算法,如间隔分歧散度 MDD 等。
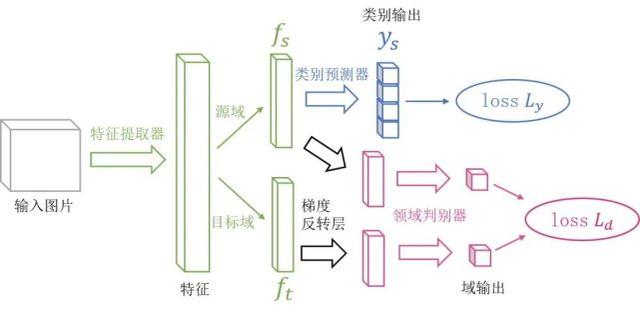
DANN 网络架构图。
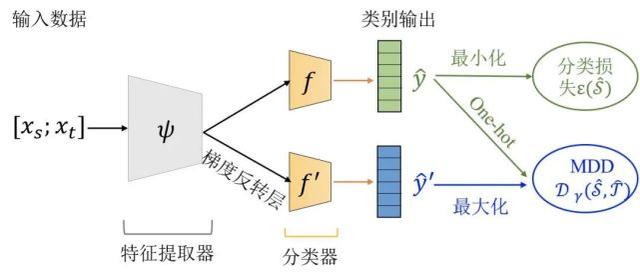
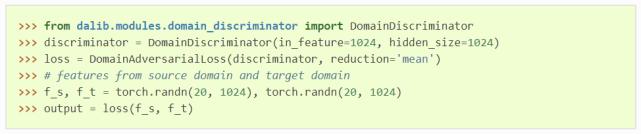
MDD 网络架构图。 上述方法在实验数据上表现出良好的性能。然而目前学术界领域自适应方法的开源实现存在下述问题: 复用性差。领域自适应方法和模型架构、数据集耦合在一起,不利于领域自适应方法在新的模型、数据集上复用。 稳定性差。部分对抗训练方法随着训练进行,准确率会大幅度下降。 针对这些不足,深度领域自适应算法库(DALIB)设计的初衷就是:用户通过少数几行代码,即可将领域自适应算法应用到实际项目中,无需考虑领域自适应模块的实现细节。 易用性 DALIB 将现有领域自适应训练代码中的领域自适应损失函数分离出来,按照 PyTorch 交叉熵损失函数的形式进行封装,以方便用户使用。 领域自适应损失函数也和模型架构进行了解耦,不依赖于具体的分类任务,所以算法库很容易扩展到图像分类以外的机器学习任务。 如下所示,使用两行代码即可定义一个与任务无关的领域对抗损失函数:
各种领域自适应损失函数中有一些公用的模块,例如所有算法中都用到的分类器模块、对抗训练中用到的梯度反转模块和领域判别器模块、统计距离中用到的核函数模块等。 这些公用模块和提供的领域自适应损失函数是分离的。因此,在 DALIB 中,用户可以像搭积木一样,重新定制自己需要的领域自适应损失函数。 例如,在核方法中,用户可以自定义不同参数的高斯核函数或其他核函数,然后将其传入到多核最大均值差异(MK-MMD)的计算中。
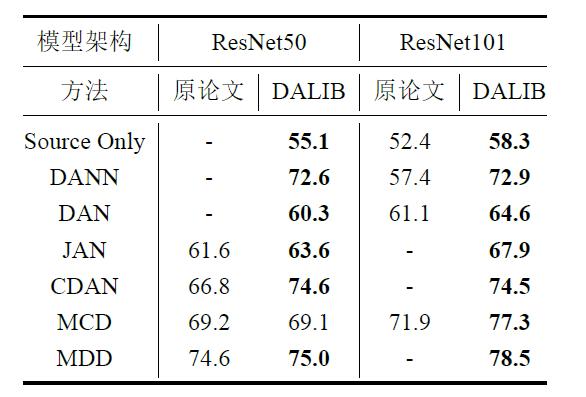
目前,所有的模块和损失函数均已提供详细的 API 说明文档:https://dalib.readthedocs.io/en/latest/。 稳定性 领域自适应算法研究往往关注方法的创新性或理论价值,而忽视了工程实现中的稳定性和可复现性。在复现现有算法的过程中,出现了部分算法准确率不稳定的问题。DALIB 通过对数值计算方面的改进,解决了这些问题。(具体实现此处不再展开。) DALIB 在常见的领域自适应基准集上的测试准确率都比原论文汇报准确率高,在部分数据集上的准确率甚至高出 14%。下图分别是 Office-31 和 VisDA-2017 三个基准集上的测试结果:
Office-31 上不同算法的准确率。
VisDA-2017 上不同算法的准确率。 (编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |