记一次上千节点Hadoop集群升级过程
|
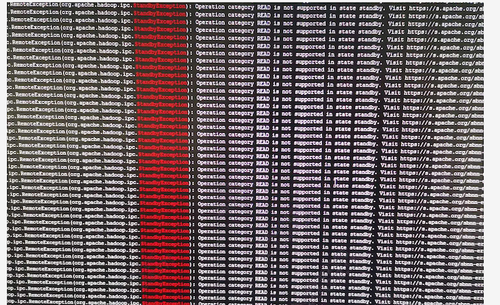
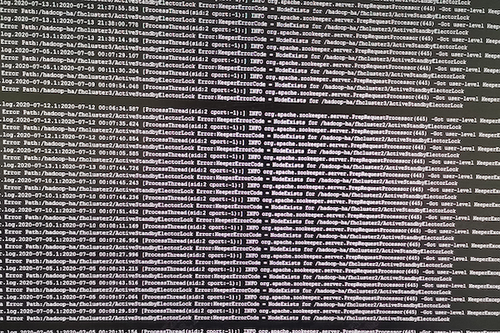
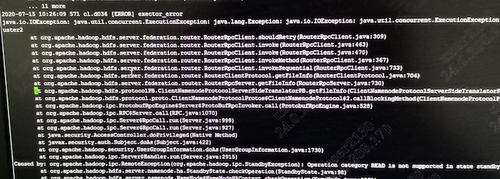
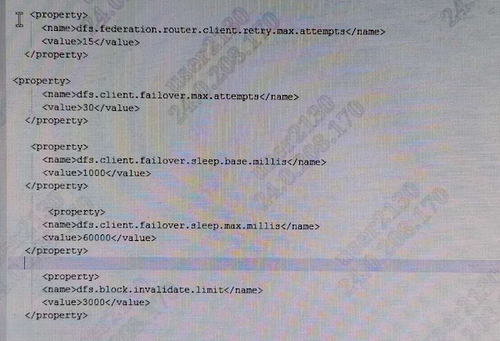
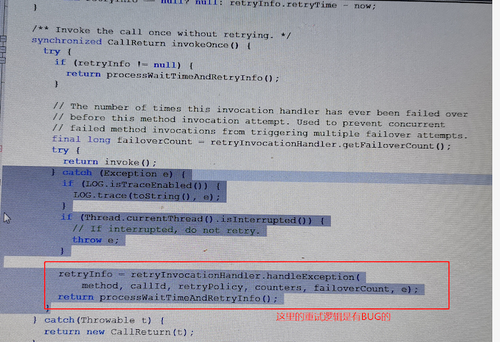
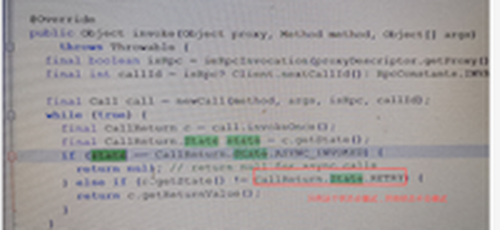
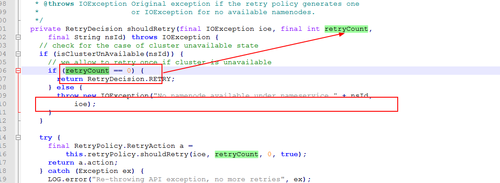
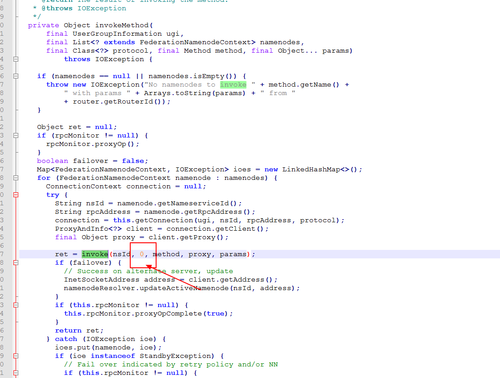
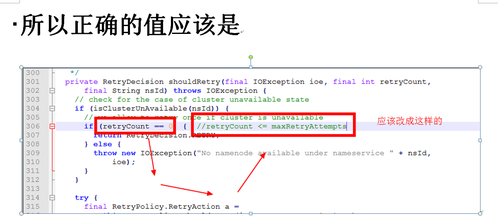
继《记一次超万亿规模的Hadoop NameNode性能故障排查过程》之后,虽然解决了Hadoop2.6.0版本在项目中的问题,但客户依然比较担心,一是担心版本过老,还存在其他未发现的问题;二是按目前每天近千亿条的数据增长,终究会遇到NameNode的第二次瓶颈。基于上述原因,我们决定将当前集群由Hadoop2.6.0版本升级到Hadoop3.2.1版本,且启用联邦模式。 历时2周,我们将录信数据库LSQL的源码进行了修改,适配Hadoop联邦机制,以期达到扩容至上万节点的能力。 因为是数十亿数据规模的生产系统,无论是丢数据还是长时间停服务都是不可接受的,所以客户方和录信侧都非常慎重,做了大量的前期准备,进行了多次升级演练,包括各种情况的回退方案、数据丢失的挽回方案、升级后的功能性能验证,大大小小做了十几次测试。但即使做了充分的准备,我们还是遇到了几个预想不到的问题。 永不退缩是录信最深的执着,经过一周的日夜奋战,集群终于成功升级到社区最新Hadoop3.2.1版本,启动3个联邦,彻底解决NameNode负载问题。 记录下升级中遇到的问题,分享给大家,希望能有一点小小的贡献,让大家越过录信趟过的雷! 一、 跨多个联邦后,速度没有变快,反而变慢 理论上,升级成跨联邦机制,读写请求会分别均衡到三个不同的NameNode上,降低NameNode负载,提升读写性能,然而事实是NameNode负载不但没有降低,相反变得非常非常慢。 集群卡顿的程度,对于生产系统来说是不可用的,升级已经进行了三天了,再不解决就要立即启动回退方案。心有不甘,连夜奋战。 抓了堆栈,知道主要问题还是NameNode卡顿,生产系统已经不能继续调查下去了,不想回退,就得让系统可用,那就得从我们最熟悉的地方下手---修改录信数据库LSQL,给所有请求NameNode文件的地方加上缓存,只要请求过的文件,就缓存下来,避免二次请求NameNode。 LSQL修改后NameNode状态有非常大的改善,系统基本可用。但具体为何升级到联邦后NameNode的吞吐量不升反降,我们没能给出合理的解释,只能考虑为历史数据还在一个联邦上,不均衡,之后随着新数据的逐步均衡,会有所好转,但这并不准确可靠。 二、 升级联邦后LSQL不稳定总挂掉 升级后,几乎每隔几天LSQL就会挂掉一次。 观察录信数据库LSQL的宕机日志,发现有大量的如下输出,证明Hadoop NameNode经常位于standby模式,导致Hadoop服务整体不可用,从而引起录信LSQL数据库宕机。 进一步分析NameNode发现Hadoop的NameNode并未宕机,active与standby都活着。结合Zookeeper日志分析发现,期间发生了NameNode的activer与standby的切换。 这里涉及两个问题,一是为什么发生了主备切换,二是切换过程中是否会导致服务不可用。 针对主备切换的原因,经过对比切换发生的时间,发现切换时NameNode做了比较大的负载请求,如删除快照,或者业务进行了一些负载较大的查询。这很有可能是因为NameNode负载较高,导致的Zookeeper链接超时。具体为什么NameNode负载很高,这个我们在后面阐述。 至于切换过程中是否会导致服务不可用,我们做了测试。第一次测试,直接通过Hadoop 提供的切换命令切换,结果切换对服务没有影响。第二次测试,直接将其中的Active NameNode给kill掉,问题复现了。可见在Hadoop 3.2.1版本里,active 与standby的切换,在切换过程中,是存在服务不可用的问题的。我们针对报错位置进一步分析如下: 看RouterRpcClient类的设计实现,应该是存在failover的逻辑。相关配置参数key值如下。 最终分析RouterRpcClient.java这个类,发现其设计逻辑是有问题的,虽然预留了上面那些参数,但没有生效,NameNode在主备切换过程中,存在两个NameNode同时处于Standby的过程。并且这个阶段,会直接抛错,导致因报错而服务不可用。 我们详细阅读了该类的实现,发现该类虽然预留了重试的逻辑,但是这些重试的逻辑并没生效,存在BUG,故我们对此进行了修复。修复后录信数据库LSQL的宕机问题不再出现,如下是涉及源码的分析过程: 如下是修复版本后,router重试过程中记录的日志: 三、 录信数据库LSQL查询的时候间歇性卡顿 Hadoop升级到3.2.1版本后,录信数据库LSQL会出现间歇性的卡顿情形,导致业务查询页面总是在“转圈圈”。 到现场后第二天遇到了该现象,经过了一系列的排查和追踪,最终定位在Hadoop 的NameNode卡顿。具体体现在进行一次ls操作,会卡顿20~30秒的时间。进入NameNode节点的机器观察负载情况,发现CPU的负载占用在3000%上下。 (编辑:应用网_阳江站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |